Progress Report September and October 2020
The development that took place in the last two months mostly focused on streamlining the part creation and review process.
Pull request review bot
It all started with opening an issue discussing about how to make it easier to get parts merged in to the horizon-pool repo.
One of the major obstacles in reviewing pull requests was that the process of checking out the PR, updating the pool and having a look at each item was rather laborious. To alleviate this, I had the idea of a bot that posts a summary of all items in the PR to the comments so one doesn’t even need to leave GitHub.
The initial plan involved triggering a GitHub action every time the
pull request is updated. This however is complicated by the fact that
the bot needs access to the GITHUB_TOKEN secret for posting the comment,
but actions triggered by PRs run the workflows defined in PR, so can’t
be trusted with secrets. Fortunately, GitHub actions had just gotten a
new event
type
that runs the workflow files from the PR’s target, so the workflow gets
handed the secrets required for posting comments. In the end, I didn’t
need any of this since I figured it’s more convenient to trigger the
bot by posting a comment with a specific trigger phrase.
Another detail that didn’t pan out as devised was implementing the bot in Python based on the Python module as that’d have involved exposing all of the pool items’ internal details such as a Unit’s pins in the Python API. I didn’t really feel writing tons of glue code to accomplish this, so I wound up implementing the bot in C++.
For easy use in GitHub actions, it’s packaged as a docker image. At the time of writing, it’s based on the yet-to-be-stable Debian bullseye as the copy of osmesa that’s packaged in buster is broken due to a bug that got fixed upstream over a year ago. I wanted to file a bug in the debian bugtracker, but got demotivated by the overly complex process.
As described earlier on, the
workflow
is triggered by a comment beginning with the trigger word Bot!. To
avoid pulling the docker image on every comment, even if it’s on an
issue, the workflow is divided into two jobs. The first job checks if
the comment matches the trigger word using a fork of the
Khan/pull-request-comment-trigger action.
The second job that pulls and runs the docker image thus only runs if
the bot was triggered.
The bot itself then updates the pool that got pulled by the workflow script and uses libgit2 to figure out which files got changed in the pull request. Through some rather lengthy recursive SQL queries it prints a list of changed items and their relationships.
For each item that’s part of the PR, it’ll print all of its details that are necessary for determining whether it’s fit for being merged into the pool repository. To help this, the bot also runs checks to automatically point out common mistakes.
To aid visual review of symbols and packages, the bot includes a rendering of the item in its output. Unfortunately, GitHub’s API doesn’t support attaching images to comments, so I had to host the images externally. The first approach that came to my mind was to use an S3 bucket and cloudflare as I’ve read about that combination as a cheap way to host static content. After trying to set this up, I decided this wasn’t for me due to excessive complexity of AWS and cloudflare only being available for top level domains. Rather than this rube-goldberg contraption of multiple cloud services, the bot uses another repo that it pushes to using a deploy key.
For the in-pad text rendering in packages, I resurrected the code that renders the in-pad text using vector fonts. That code was used in the board editor until it got replaced by the more efficient MSDF-based rendering.
More checks
Initially, all of the checks for Units, Entities and Parts were locked up inside the PR review bot, meaning that people opening PRs will only get feedback once the bot has run. To give instant feedback instead, I decided to move these checks into the common code that’s used by both the pool manager and the bot.
Unit, Entity, Part
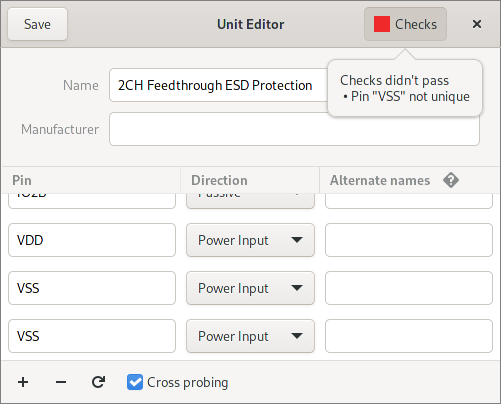
All of these editors grew a “Checks” button in the header bar that provides live feedback on the check status.
Symbol
To take some of the manual work out of reviewing Symbols, the Symbol editor got support for checks as well. These check for correct placement of pins and text among other things.
Improved GitHub authentication in the pool manager
Since its inception, the remote tab in the pool manager that simplifies submitting PRs to the horizon-pool repo without having to use git made use of password-based authentication. Since I wasn’t comfortable with storing passwords persistently, users had to reenter their password every time they submitted a PR.
Needless to say, that this is far from good user experience, especially since it didn’t work well with two-factor authentication enabled. The final push to to improve this situation was GitHub announcing to turn off password-based API access near the end of 2020.
So I had a look how other tools that also use GitHub’s REST API handle authentication. The GitHub desktop app uses OAuth with the redirect URL being a custom protocol that’s handled by the app. Since I didn’t want to rely on protocol handlers as these might not be set up correctly if the user is running Horizon EDA directly from the build directory without installing it, that option wasn’t for me.
A few months back, GitHub CLI 1.0 made the news, so I was curious how it does authentication. Trying it out and having look at the sources revealed that it uses the OAuth 2.0 Device Authorization Flow. Compared to regular OAuth, this doesn’t need any protocol handlers and fits the bill in other aspects as well, I set out to to add implement it in the pool manager:
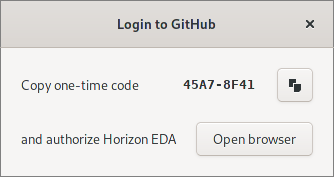
After clicking the login button in the pool manager, the user receives a one-time code.
Once having entered the code on the page linked in the login window, they’ll get the standard OAuth authorisation page:
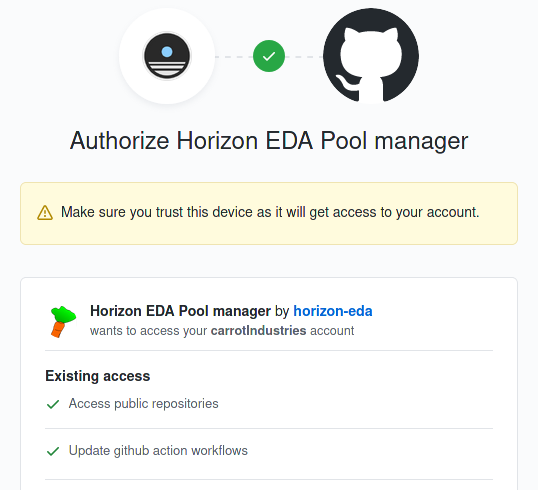
Access to workflows is required since the forked pool repo also contains workflows.
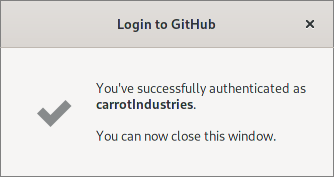
A few seconds after authorizing the pool manager, the pool manager receives the OAuth bearer token and the user is logged in:
Support for updating PRs
Another nuisance about the remote tab in the pool manager was that
there was no easy way of updating pull requests. This has somewhat
bothered me for the entirety of its existence, but I couldn’t come up
with a robust way of implementing it. For creating PRs, the pool
manager maintains a clone of the forked pool in the .remote directory
and copies items into it as needed. Updating a PR then could involve
any arbitrary action such as removing, renaming or adding files to the
existing PR branch.
After mentioning this in a pull request, in the pool repository, Stephanie suggested on IRC to create a new commit and force push that one to get around the difficulties of updating an existing branch. As this idea seemed reasonable to me, I started thinking on how to implement it and came up with a way that doesn’t require force pushes. Explaining it requires diving a bit into how git works internally:
Even though most git interfaces show commits as diffs, each commit is in fact a complete snapshot of all files in the repository, represented by a so-called tree object. Thanks to git’s content-addressable storage, a particular version file is only stored once and can be referenced by more than one tree. Tree objects get created from the contents of the index (staging area) when committing. Usually, the working directory and index contain the files of the commit that’ll be the parent of the to-be created commit and the desired changes.
However, nothing’s preventing us from using the files from a different commit as the starting point for our changes. When updating a pull request, the pool manager finds the merge base for the PR branch and the master branch to get the commit the PR is based on. It’ll then check out this commit, copy the files the user wants to merge, adds them to the index and writes a tree object from the index. This three object is used to create a commit whose parent is the latest commit on the PR branch. That way, we always start from a known-good state and only get the changes the user intended to do without having to worry about renames and the like.
Version info in files
The on-disk json format has been continuously evolving along the application to support new flags and features. These changes were always done in such a way that it’s always possible to open files created with an older version. However, when saving a file, it’ll always be saved in the latest format. Opening and then saving such a file in a prior version will then lead to the details not supported in that version to be erased from the file.
To prevent this from happening and to alert users about converting a file to a newer version, we now have per-file version information and the issue for it is finally closed. It’s important to note that the version stored in the files relates to the version of the file format itself, not directly to the version of Horizon EDA the file was created in. This allows for more fine-grained alerts since these will only appear if a newer version of the application actually made changes to the file format.
When saving a file will upgrade its version this is what the user will
see:
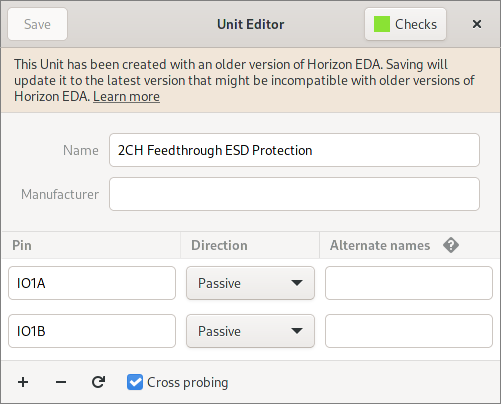
If the file was created in a newer version, it’s opened read-only:
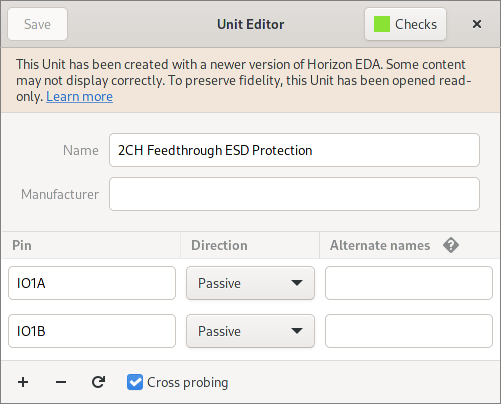
The learn more link leads to the documentation on the versioning scheme.
To be honest, this should have been in there at least since version 1.0, but oh well. Alt least we can now implement things such as adding directions to alternate pin names.
Version 1.3.0
As per the release schedule, version 1.3.0 got released on 2020-10-29. See the changelog and this and the prior progress reports for features that made it into the release. The list of new features is a bit shorter than usual since the pull request review bot isn’t part of the released application.