Progress Report November and December 2020
Pool reload in schematic and board
Since over 3 years, symbol and package editors supported reloading the pool to receive changes made to units/pads without restarting the editor. I didn’t implement this for board an schematic editors right away as reloading all pool items can have far-reaching consequences such as deleted pins or gates that cause broken references.
Revisiting this, it occurred to me that this the problem is already dealt with when opening a board or a schematic. To make use of this code, reloading the pool is implemented as serializing the document to json in memory, clearing the pool and reconstructing it from the temporary json object as if the editor was reopened. This might not be the most elegant solution, but it gets the job done with little additional complexity.
Pool update speed improvements
Horizon EDA caches metadata like name and UUID of pool items (Parts, Entities, etc.) in a SQLite database for fast and convenient lookup. This database has to be kept up to date as the user edits items in the pool. Originally, editing a single item required the whole database to be rebuilt from scratch as the pool update was all-or-nothing. Depending on the machine, that process could take in the order of half a minute. This got really annoying as the pool grew bigger, so last year I added support for partial pool updates so that only the item (and its dependants) that got edited is updated. This made the pool updates after edits almost instant.
Still, updating the pool from-scratch, as it’s required when switching branches, took quite long so I set out to make that process faster as well. For the record, updating a pool with about 30000 parts took 26 seconds on my machine. My go-to tool for figuring out why my code is running slower that I’d like it is perf in combination with Hotspot to produce pretty flame graphs. From the flame graph below, we can easily spot that preparing SQLite queries takes its time:

This was quite a low-hanging fruit since all that’s needed is preparing the queries once and reusing them afterwards. With this enhancement in place, the pool update time is down to 21 seconds and the flame graph looks like so:

It might not be directly evident from the flame graph, but each of the 30000 parts is loaded from disk and parsed 3 times:
- During discovery as the dependency graph is built
- Actually inserting the part into the pool
- Inserting the part’s parametric data into the pool
To avoid loading the part from disk in step 2, the json document parsed in step 1 is saved in-memory for later usage. This optimisation reduced the time needed for a complete update to 18 seconds. Reusing the part from step 2 in step 3 shaved off about 2 seconds, leaving us at 16 seconds.

The pool update itself now is down to executing SQLite queries and
loading parts from disk once, so there’s not much more to do in that regard for
now. Looking at the UI thread to the right however, it’s obvious that
trying to display (gtk_label_set_markup) every filename the pool
update encounters is taking a lot of CPU time.
Even though having the filenames zip by while the pool updater is doing its job may give the user a warm an fuzzy feeling about the computer working hard, as it’s often portrayed in movies, actually provides very little benefit since the filenames aren’t really readable due to only being visible for a fraction of a second.
Showing only the item type that’s currently being worked on in combination with improved locking brings down the pool update to slightly less than 10 seconds, about a 2.5× improvement compared to where we started!
On Windows, where disk I/O is known to be slower, the speedup is even more dramatic. Updating 30000 items went down from 74 seconds to 16 seconds, almost 5 times faster than before.
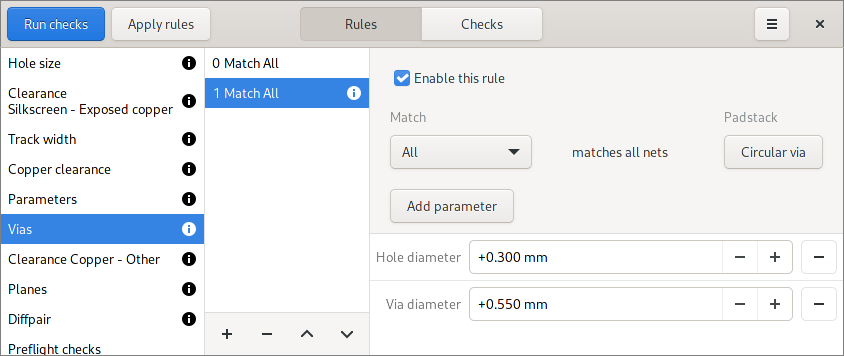
Rule import/export
For quite some time now users have been asking for design rule import and export. As written in the issue, this spares users from re-entering the board manufacturer’s design rules for each new board.
During export, only rules that match either a net class, net name regex or all nets are exported. Rules that match a net are ignored.
When importing rules, the users gets a chance to match the rules’ net classes to the ones from the board:
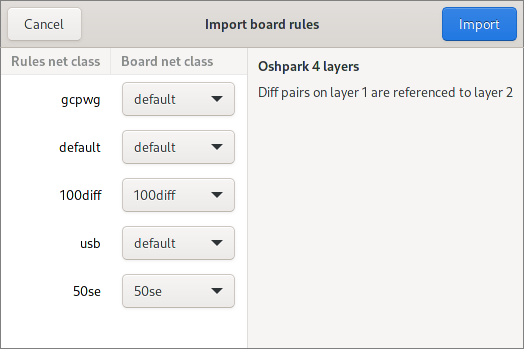
To make it easier to tell which rule just got imported and which one already was there, the imported rules are decorated with a small emblem:
Parameter program editor enhancements
The Parameters programs that go with padstacks and packages have always
been one of the not-so-intuitive aspects of the application. To make
editing a bit easier, there’s now a button to insert the
get-parameter command for a given parameter:
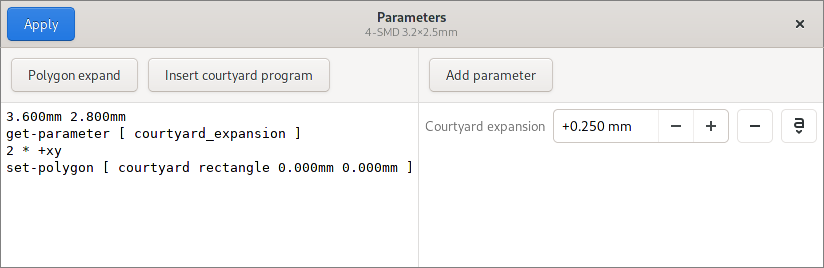
On top of that, the window title now shows the title of the document it belongs to avoid confusion if more than one window is opened at a time.
Navigation buttons for switching layers
My mouse (a trackball in fact) features forward/backward navigation buttons, as probably a lot of slightly upmarket pointing devices do as well. I’ve been pondering for a while how these could be put to good use.
Telling a friend of mine about this, he suggested to use them for switching layers in the board editor. I quite liked that idea, so now there’s an option to enable this behaviour.
Pick&place export format customisation
When adding the pick&place export in February , I didn’t have any particular export format in mind and decided to wait for people to tell me if the export format didn’t suit their (or their assembly houses) needs. That time came when people made me aware that they had to postprocess the generated CSV in Excel to have it accepted by JLCPCB’s assembly service.
To make their lives easier, the Pick&place output format is now customizable to be at least compatible to what JLCPCB expects:
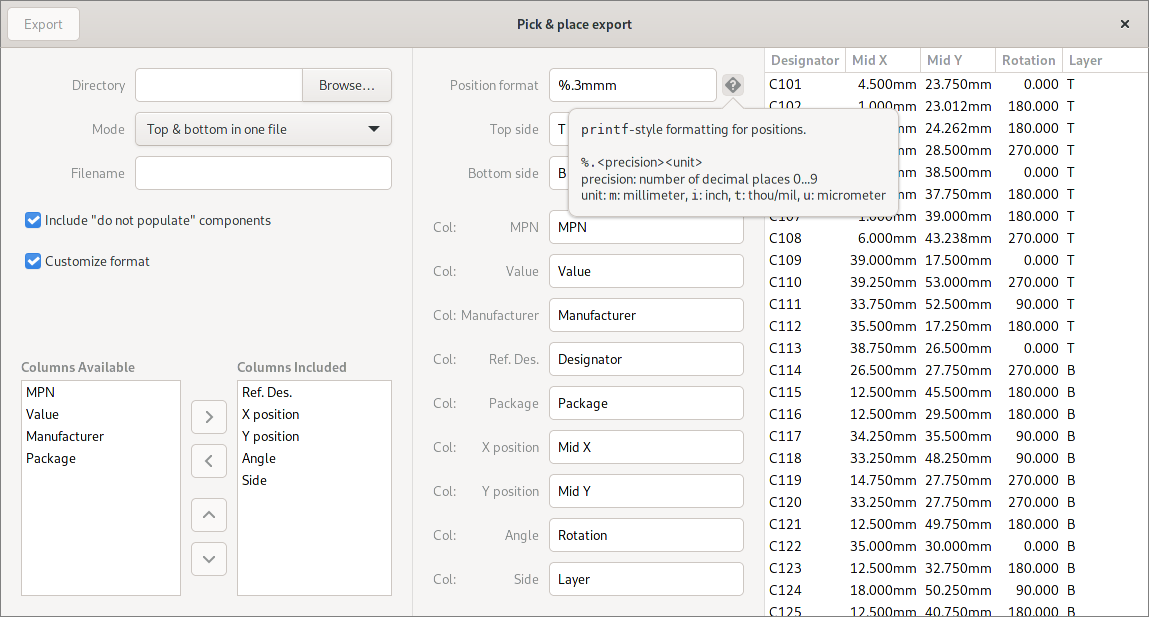
Drag polygon edge tool
For dragging tracks while keeping their slope, there’s the “drag and keep slope” tool as well as dragging using the KiCad router. The new “drag polygon edge” tool brings this behaviour to polygons by making use of the geometry calculations originally developed for the “drag and keep slope” tool:
Interactive pad editing
As suggested in issue #474, the “Edit pad” tool now provides live preview of the changes made in the dialog:
Clicking on a pad selects it in the dialog.
Intel GPU Drivers on Windows
The usual reaction to people complaining about Horizon EDA not running well on their particular GPU, especially on Windows, is to tell them that their GPU driver sucks by pointing to this blog post (guess which one’s Intel). While this is probably technically correct, it leaves everyone involved unhappy.
In one instance, people using Intel GPUs on Windows were reporting that the selection preview in the “clarify selection” menu was selecting the wrong (in fact, the previous) item on the canvas. With some guesswork involved, I added a workaround for this particular problem.
Only after people mentioned, that also text entries updated a frame too late, it seemed more and more as if the bug would be with Gtk rather than Horizon EDA. So I got hold of an Intel-based laptop running Windows, and decided to finally have a closer look at this problem myself.
Typing in an entry in the board editor window confirmed that the bug
was indeed real. Typing in a window without a GL area such as the
preferences window didn’t exhibit
the buggy behaviour. So you might ask, why does a GL area affect
widgets next to it? Normally, Gtk renders windows entirely in software
using cairo. For OpenGL, that’d require reading back the rendered
pixels from GPU memory to main memory using glReadPixels which is probably quite slow. To avoid
this, Gtk uses OpenGL for rendering everything in a window if there’s
at least one GL area. The non-GL widgets receive a cairo context to
render to as usual. The surface backing this context is then drawn to
the back buffer as a textured rectangle. GL areas draw onto a
framebuffer object. When all widgets that needed
to draw in this cycle are done, the areas in the back buffer that got drawn
to are copied to the front buffer using the glBlitFramebuffer
function. That’s why a having at least one GL area in a window invokes
different code paths for all widgets.
By now it should be clear, that we’ve definitely got a Gtk bug on our hands. The
only thing left to do before filing an issue is to come up with a way
to reproduce the bug without Horizon EDA attached. Unfortunately, none
of the examples included in gtk3-demo and gtk3-widget-factory had
the right combinations of widgets to make this bug easy to reproduce.
Rather than implementing a testcase myself, I remembered the
(undocumented?) GDK_GL environment
variable
that can be set to always to force Gtk to use OpenGL for
rendering windows even if not actually required by presence of a GL
area. With the variable set
accordingly, the bug was reproducible using one of the entry demos from
gtk3-demo, so I filed a bug
report.
As with the last OpenGL-on-Windows
bug I took matters
into my own hands. The first step obviously is getting Gtk to build. My first attempt at doing so
failed with an obscure error message hinting about paths or command
lines being too long. Having also faced this limitation when building
opencascade on
Windows a while
ago, I recalled that using
SUBST can be used to map
directories to drive letters. Much to my disappointment, this party
trick didn’t work this time since meson/ninja are too smart and undid
the drive letter substitution. So I did the obvious but not so
elegant thing and moved the build directory to C:\g. Finally, I was
able to compile Gtk and run the demos with it.
Poking at the code by means of copy/pasting snippets around revealed that the bug in the Intel driver could be
worked around by doing a glFlush and copying the back buffer to the
front buffer a second
time.
Being too impatient to wait for a new release that’ll include
that workaround, I set up a workflow using GitHub
Actions that builds
Gtk with the workaround included and publishes it on
bintray.
These packages are then used in the Windows builds of Horizon EDA.
Shortly after, Chun-wei Fan opened a merge request for an improved workaround, that eventually got merged will be part of Gtk 3.24.25.
Bugs like this and the other one three years ago make me wonder if Horizon EDA is the first (or only?) application to make use of Gtk’s OpenGL features on Windows…
Board rebuild speed
Ever since day
0
the
Board::expand
method has been central to the board editor. Its job is to bring the
board back into a consistent state after it got modified by a tool.
These are the major steps in that process:
- Copying packages from the pool into the board and optionally flipping its layers if placed on the bottom side
- Assigning nets to pads based on the netlist and propagating nets to tracks
- Recalculating airwires
To keep implementation complexity low and ensure correctness, all of these steps were done after every tool completed. It shouldn’t come by surprise that this isn’t optimal from a performance point of view, especially as boards grow more complex.
Some smart person (don’t remember who, please tell me if you know) once said something along the lines of
The best optimisation is to do less
In our case, that requires knowing what a tool modified so that the rebuild only recomputes what’s necessary. There are two distinct ways to accomplish this:
- Tools report what needs to be rebuilt when they’re done
- The data structures in the board record modifications to figure out what needs to be rebuilt after the fact.
My first approach was number 2 as this avoids touching the logic of each of the approx. 50 tools relevant to the board editor. However, after starting the implementation, this approach felt more and more Rube Goldberg-esque.
Instead, I compiled a list of relevant tools and took note of what needs to be done after the tool:
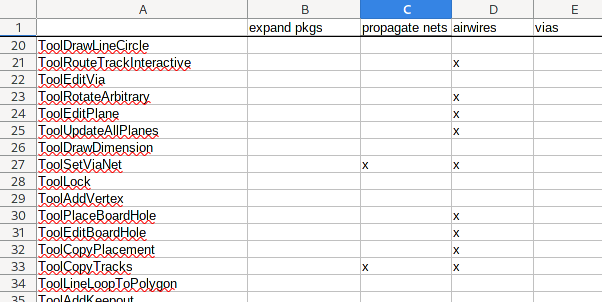
This found its way into the implementation by adding a couple of more
bits to the ExpandFlags
enum
and setting
the relevant ones
right before a tool has done it’s job.
Overall, this decreased rebuild times for tools that don’t require anything in particular to be rebuilt (such as moving a dimension) from 115 ms to 9 ms on the X-band transmitter. Deleting tracks of big nets such as GND only went down to around 60 ms, as this still requires recomputing airwires for the entire GND net.
Even though I paid close attention to not forget any edge cases, there’s still the possibility that I forgot some interactions. Don’t hesitate to get in touch if you notice things not updating anymore after certain tools.
Git tab performance
While reviewing Stephanie’s pull request that adds more than 10000 new parts, I noticed that the Git tab took unacceptably long to load, freezing the UI for more than 10 seconds.
Profiling revealed that a substantial amount of time is taken by the
GtkTreeModelSort
adapter responding to the items inserted into the store backing the
treeview that lists the diff to the master branch. As I couldn’t figure
out a way to prevent GtkTreeModelSort from updating until all items
are inserted, I tried deleting it before inserting thousands of items
and recreating it afterwards. Even though this reduced the time to
about 4 seconds, that solution seemed somewhat hacky to me. Instead, I
ditched GtkTreeModelSort altogether and moved all of the sorting and
filtering to a temporary SQLite table. This reduced the load time to slightly less than 3
seconds.
Profiling indicates that the majority of the time is now taken by libgit2 creating the diff. Blocking to the UI for 3 seconds still is far from optimal, but reviewing pull requests will more than 10000 items isn’t something a lot of users will often do. That’s why I haven’t yet bothered to move the git interaction into a background thread.
Improved arc rendering
Due to perceived implementation effort (me being lazy) arcs were rendered as series of line segments. This had the unfortunate consequence that in outline mode arcs looked like the one on the left side. Not really what one would call “outline. To improve their appearance, the OpenGL renderer now renders arcs natively, as shown on the right side.


To to so, it draws a equilateral triangle that’s large enough to contain the arc and then uses the fragment shader to turn the triangle into the desired arc.
What’s next
As per the release schedule, version 1.4 is due end of January. I decided not to attend the (virtual) FOSDEM this year, instead I’ll try to write some more blog posts.